At TripAdvisor, the devops team managed about 400 physical servers spread across three server rooms. We ordered and provisioned new hardware, scavenged parts (and sometimes whole servers) from the live site teams, replaced hard drives, installed and upgraded OSes, rebooted, rewired, and were generally on call for all manner of problems.
What a pain. I mean, seriously, who wants to be sitting in a 10º C server room, trying to snake cable through spaces clearly not meant for adult fingers? Or removing server blades, unscrewing four tiny screws, attaching a hard drive with four more tiny screws, then replacing the original four? Over and over again? And yet our ability to upgrade, update, and maintain uptime across a wide variety of heterogeneous hardware configurations was a key standard by which we were judged.
Fast-forward to Scratch, and things are completely different. We originally had a couple of DigitalOcean droplets and services set up through Heroku, as well as an S3 bucket for static files. After some consultation with our DevOps contractor, we moved almost everything over to AWS. The power of AWS isn’t so much price/performance, but rather in the surrounding constellation of services. Here’s a quick run-down of our setup:
- EC2 Instances: This is your bread and butter, the servers that run your code, manage your builds, perform automated tasks, and so on. If we were hipper, we’d probably be using docker images, but boring tech is good tech.
- Auto-Scaling Groups: What if one of our EC2 instances spontaneously combusts? Or Kim Kardashian tweets about us and our servers start melting through the floor? Or we want to sunset one of our server clusters, one server at a time? Auto-scaling groups let us add or delete servers from a cluster by editing a single number in the config, with post-creation configuration handled automatically by our puppet server.
- Elastic Load Balancers: ELB is useful for several reasons – first, because it balances the load across multiple servers in an auto-scaling group. Second, because it terminates SSL, which simplifies our server configuration. Third, because it acts as a firewall – your servers can still be pwned (OF COURSE), but setting up your security groups correctly means that the outside world never touches them directly.
- Security Groups: Instead of wading through iptables, EC2 security groups provide an easy way to restrict access to your private virtual cloud. For example, the following is approximately what our setup looks like:
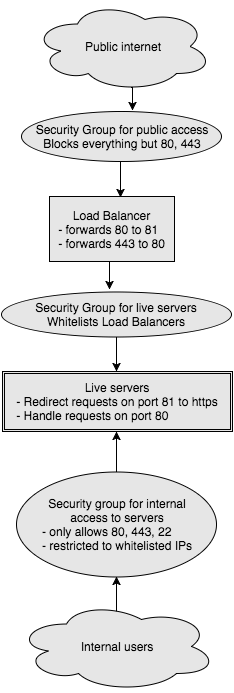
- Route 53: Although there are a couple of subtleties, Route 53 allows for pretty simple DNS setup. Nothing much to it.
- S3: A big hard drive in the sky. This is where we store releases, backups, archived logs, and static files. It’s also useful for setting up backups with 3rd party services, to whom you can grant read/write privileges to specific buckets.
- CloudFront: A dead simple CDN that hooks up to S3 and “just works” (you can also point it at an http server). Honestly, the hardest part of setting it up was figuring out the command line parameters to upload files to S3 with the right headers[1].
- Certificate Manager: If you’ve ever had to get an SSL cert from one of the usual providers, you’re already starting to experience flashbacks and intense feelings of anxiety and rage. It’s an expensive, time-consuming, confusing, and incredibly frustrating process. The certificate manager, on the other hand, snaps in perfectly with the rest of the tools – the newly purchased cert is immediately available to the ELB and CloudFront in a drop-down menu.
- Identity and Access Management: A little daunting at first, IAM is an incredibly powerful tool to allow specific access at the resource level. So, for instance, you can grant write access to an S3 bucket to one server that needs to archive a file, and read access to another so that it can process the file. Or you can give a user access to a specific set of API commands on some servers, while completely restricting others. You can create alternate accounts for team members (each with 2fa), so that you don’t have to share master AWS login credentials. It’s a powerful tool, once you figure out how to use it.
- Redshift: We use Looker for analytics, which in turn expects data to be in Redshift. Using Redshift isn’t terribly difficult – it mostly acts like an old version of postgres (from which it was forked). Configuring it, on the other hand, is a bit more complicated, and not something we’ve spent a lot of time tuning. You can set up multiple clusters, with multiple machines, which can be of different sizes, with different numbers of IOPS, etc., etc. No doubt we could be getting better performance if we only added more machines to our clusters, or gave them more memory, or made them beefier, but for now it’s working well enough.
- RDS: So, we aren’t using this, but I wish we were. If I were building a new system, I wouldn’t worry about setting up my own database servers, I’d just provision some RDS servers and be done with it.
- CloudFormation: The one ring to bind them all. CloudFormation is a fairly simple UI that takes a pretty complicated configuration file, and sets up an entire “stack” composed of as many of the AWS services as you want. So, for instance, if you need to set up a new test stack composed of some EC2 instances, an auto-scaling group, ELB, security groups, and IAM rules, you just specify it all in a JSON file, upload it to CloudFormation, and go get a coffee while it does its thing. Of course, you won’t want to hand-tune this JSON file – troposphere is the standard tool to generate the config files.
Of all the critical pieces of our operational infrastructure, Puppet and Jenkins are the only two which aren’t provided by AWS. And while they don’t yet provide Jenkins-as-a-Service (JaaS?), you can use Chef in AWS OpsWorks, which is reason enough to give it a hard look.
For most companies, operational stability is both a foundational requirement and a distraction from the “real” work of building a product. I.e., unless you’re in the business of building out operational infrastructure, your limited technical resources are mostly – should mostly – be focused on creating a great, differentiated product, not tweaking server configs. Using AWS has allowed us to get on with our work without worrying too much about the operational issues of running a site. If you’re lucky, there will come a time when it makes sense to manage them yourself, but until then, it’s nice to be able to hand them off and focus on the things your company actually cares about.
aws s3 cp foo.js.gz s3://my-cdn-bucket/foo.js \ --content-encoding gzip \ --cache-control max-age=31536000 \ --grants read=uri=http://acs.amazonaws.com/groups/global/AllUsers

This is good and simple case study and sums up nicely the evolution that AWS has brought in our lives. And through our experience at nclouds.com, we can attest to the fact that many big organizations are already moving towards AWS or other cloud platforms.