As I mentioned in my last post, my startup has just shipped its first public release! It’s a good feeling to be iterating instead of writing from the ground up, and I thought it would be a good time to take a deep breath and reflect on where we’re at.
Architecture
Scratch is built using an entirely Javascript stack. We use Mongo as our data store, NodeJS and Express as our server, and ReactJS to build a single-page app. nginx manages the connections, and puppet handles all configuration. We use a variety of AWS services, which I’ll detail below. Here’s what it looks like:
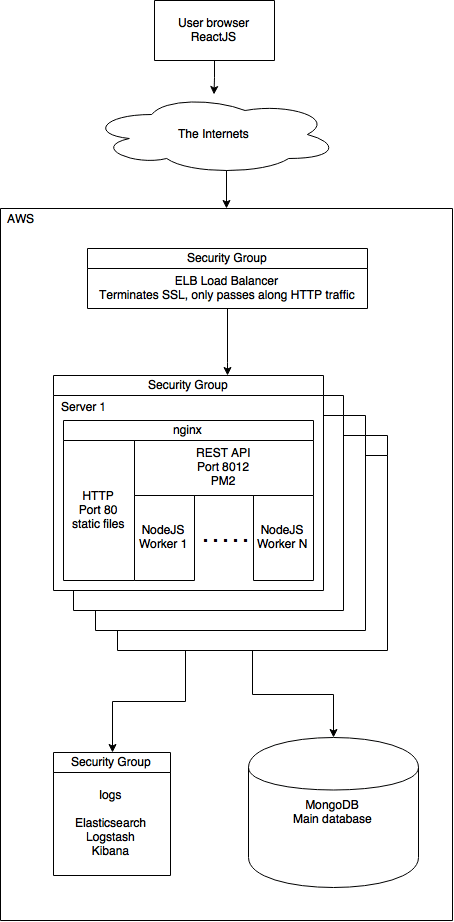
We have a single point of entry for all requests – through the load balancer, which terminates SSL and passes all requests to port 80 on one of the N servers. nginx takes over from here, either serving a static file, or passing the request to Node. Node is single-threaded, so we’re planning on using PM2 to manage multiple Node processes.
Every server (user-facing, test, release, logging, puppetmaster, etc.) has a security group in front of it to restrict open ports to the bare minimum. The load balancer blocks everything but ports 80 and 443. The user-facing servers block everything but 80 and 81[1], and all other servers are completely blocked from external access.
AWS
Over the years, Amazon has rolled out an incredibly powerful, complete array of services. When I first started using AWS (many, many years ago), I had a couple of EC2 instances, some security groups, and not much else. Our current set up is significantly more sophisticated, and allows us to do some pretty interesting things.
- EC2. Servers, drives, load balancers, and security groups are all handled through EC2. We also use an auto-scaling group, which allows us to specify how many servers we think we should have. If a server is misbehaving, we can simply terminate it and another will automatically be provisioned and launched.
- S3. Releases and backups are stored here.
- IAM (Identity and Access Management). This allows extremely fine-grained access control to different API commands. As an example, if you want your release machine to know which machines it should be updating in your stack, then you’ll need to give it access to the “CloudFormation:DescribeStackResource” command – which you can do without giving it access to anything else.
- Route 53. All of our DNS is handled through Route 53.
- CloudFormation. Instead of building each hardware stack by hand, we load a configuration into CloudFormation, which automatically sets everything up for us. EC2 instances, auto-scaling group, security group, load balancer, IAM permissions, etc. This is so easy that setting up a new set of servers (e.g., a test stack that’s identical to the live one, or a stack for branch testing, etc.) is a matter of minutes, not hours or days. (I did this last night to set up a branch testing environment, and the actual “work” involved was running a python script to generate the config, uploading it to AWS, and waiting for 5 minutes – pretty nifty)
Puppet
The glue that holds everything together, and in my mind the most important utility in the DevOps toolkit, is puppet. No additional configuration needs to be done when a server is provisioned, because puppet is called and knows how to set the server up correctly. Releases are a matter of building code, putting it into S3, and kicking off a puppet run. Scaling our configuration up or down can be accomplished by adjusting a single number in the auto-scaling group – everything else is handled automatically by AWS and puppet.
nginx
Another critically important tool, simple and powerful. We use nginx as a fairly straightforward reverse-proxy, either serving static files or sending requests to the backend based on URL path. It’s possible to do the same thing with Apache, of course, but nginx is small, fast, and optimized for the task.
Logging
Each of the servers runs a logstash-forwarder process to send its logs over to our ELK server, which aggregates and orders them according to timestamp. We used standard log4j-style logs for a little while, but it quickly became clear that providing structured data to elasticsearch would make analysis easier, and make our log “format” less brittle. So, we refactored all of our logging statements into JSON objects with a standard set of fields – adding a new field to a log line requires no additional work on the parsing side, since the ETL is expecting an arbitrary JSON object. Time will tell if this was a great or terrible idea, but things look good so far. Kibana doesn’t have the most straightforward UI, but it’s already creating value by giving us realtime access to error logs.
Lessons learned
Not gonna lie – coming from the much more conservative technology stack at TripAdvisor, I was extremely hesitant about adding all this technology into the mix. We’d contracted a senior DevOps engineer to set things up, and though he put a significant effort into documenting what he’d done and getting us up to speed, it still took a fair amount of time to get comfortable with the system once he left (we knew up front that we only had a month of his time). What I didn’t realize at the time, though, was what a gift we’d received, and if you’re reading this Wes, know that we’re very, very appreciative of the great work you did. Seriously – you rock, man.
It also made it clear that configuration management is the key skill to look for in a DevOps engineer. Whether puppet, chef, ansible, or salt, you need someone who knows their toolset and is meticulous about managing everything through it – no exceptions. When you can nuke and provision machines in a completely automated fashion, good things happen. Jenkins automation becomes trivial. You don’t hesitate to do necessary maintenance work due to fear of unknown consequences. You can add new packages to a machine and test – over and over, and in parallel if necessary, in a completely reproducible fashion. Cattle > pets.
Websockets are hard. Scratch has a chat feature, and we had two different ways to communicate with the backend – a standard RESTful API, and a websockets-based chat mechanism. This worked fine on our dev machines, and when we had exactly one server. But give that server a couple of friends and put it behind a load balancer, and bad, non-deterministic things started happening. There are blog posts that promise to explain how to manage the websockets / ELB / nginx troika, but we were never able to get it to work consistently. We tried a couple of bizarre server topologies that only made things worse, and in the end got rid of websockets and settled on the simpler, far more robust layout shown above.
Node is easy to get up and running, but has its limitations. Coming from a tomcat / java world, it’s easy to get annoyed that Node isn’t multi-threaded. Besides having to manage processes yourself, one of the frustrating and unexpected problems this creates is that there’s no equivalent to ThreadLocal, and no way to pass a variable through an entire request without putting it into every function’s parameter list, every Deferred, Domain and Promise call (which, as you might imagine, would be extremely painful to do). Ideally, you’d like to associate a unique identifier with each HTTP request, then log that on every log line. This doesn’t appear to be possible without major uglification of the codebase. On the other hand, Node comes with an incredible ecosystem of modules, and many of the things you need to implement have probably already been written by someone else.
React has turned out to be a good choice. It’s pretty straightforward to pick up, easy to read, acceptably performant, and continuing to gain in popularity (important in recruiting). And besides, if we hadn’t switched to React, I’d have had to learn Angular :).
Future directions
As I mentioned above, we haven’t yet made the switch over to PM2, which will allow us to manage multiple Node instances per machine – we’ll need to do some load testing to determine the optimal number of machines / processes, which I hope to detail in some future post. Also, we’re likely to move from Mongo to Postgres at some point – Postgres has a JSON column type, appears to be significantly faster, and gives us the flexibility to transition to a traditional relational model, if needed. There’s plenty more to do, but having a solid, fully-puppetized framework gives us a great base to start from.
WE’RE HIRING
We’ve got a great vision, a new product, funding, and a great location – if you’re an engineer looking for a fun, collaborative, intellectually challenging environment, send me an email and let’s chat!
[1] A little confusingly, http requests to the site (which are made to port 80) are directed by the load balancer to port 81. nginx (running on the servers) knows that anything coming in on 81 needs to be redirected to https. When the browser redirects to the correct URL, the SSL connection is terminated at the load balancer, and directed to port 80 on the server.

Great writeup Dan. Any thoughts on EmberJS vs ReactJS?
I wish I could but I unfortunately don’t have any experience with Ember. From the outside, it looks a little like what would happen if you replaced PHP (or JSP) with Javascript, but that’s probably completely unfair. Please feel free to correct me… :)
Hi Dan, great post, as always! Do you have any thoughts on Docker, and where that would fit in your devops toolchain?
Without having actually used it, I find the promise to be pretty cool, it seems like it really makes the configuration management piece better, PLUS it make developer environments as similar to production as possible. Maybe?
Docker definitely ranks very high on the cool-o-meter. I’ve considered whether we should deploy containers instead of full-on servers (there’s another Amazon service for that, as it happens), but I don’t feel comfortable enough with it yet. It’s the way things are going, though. We already use Vagrant to do puppet testing, and it’s only a matter of time before we look back on the days of deploying entire systems with a bit of nostalgia…
Hi Dan —
Do you have anything to say about your analytics stack? I recently stumbled across this: https://github.com/peaksandpies/universal-analytics, which could be right up your alley.
Great read, thank you. Can you elaborate a bit more on what was going wrong with websockets?
Hi Steve, thanks! As for websockets, we were never able to get them working consistently with multiple servers (or even a single server) behind an AWS ELB. Everything I read online went something like “this is hard, but can be accomplished by following these straightforward instructions: 1) something concrete, 2) something concrete, 3) something concrete, 4) perform some vague work of magic, 5) something concrete.” We were never able to figure out step 4, or to determine if the problem was on our side (most likely), or something fundamental to ELB.
As for what would happen, the client would try to connect to one server, then wouldn’t be tied to that server for future communication. It would switch back and forth between servers, spew Javascript errors on the client side, connect correctly for a short period, then lose its connection again. After struggling with it for a while, we decided that removing it wouldn’t negatively impact our app, and would simplify things. It’s possible we would have figured it out eventually (assuming it was a problem on our side, as was likely), but it was easier just to get rid of it.
Thanks Dan, great information, I wasn’t aware of the amount of work involved until someone referred me to your article. Glad you found a good workaround.